Groq 介紹
Groq 的主要產品是 LPU (Language Processing Units),能夠大幅提升模型的推論速度,這表示模型回答的速度加快,比 GPT-4o 快了數倍。
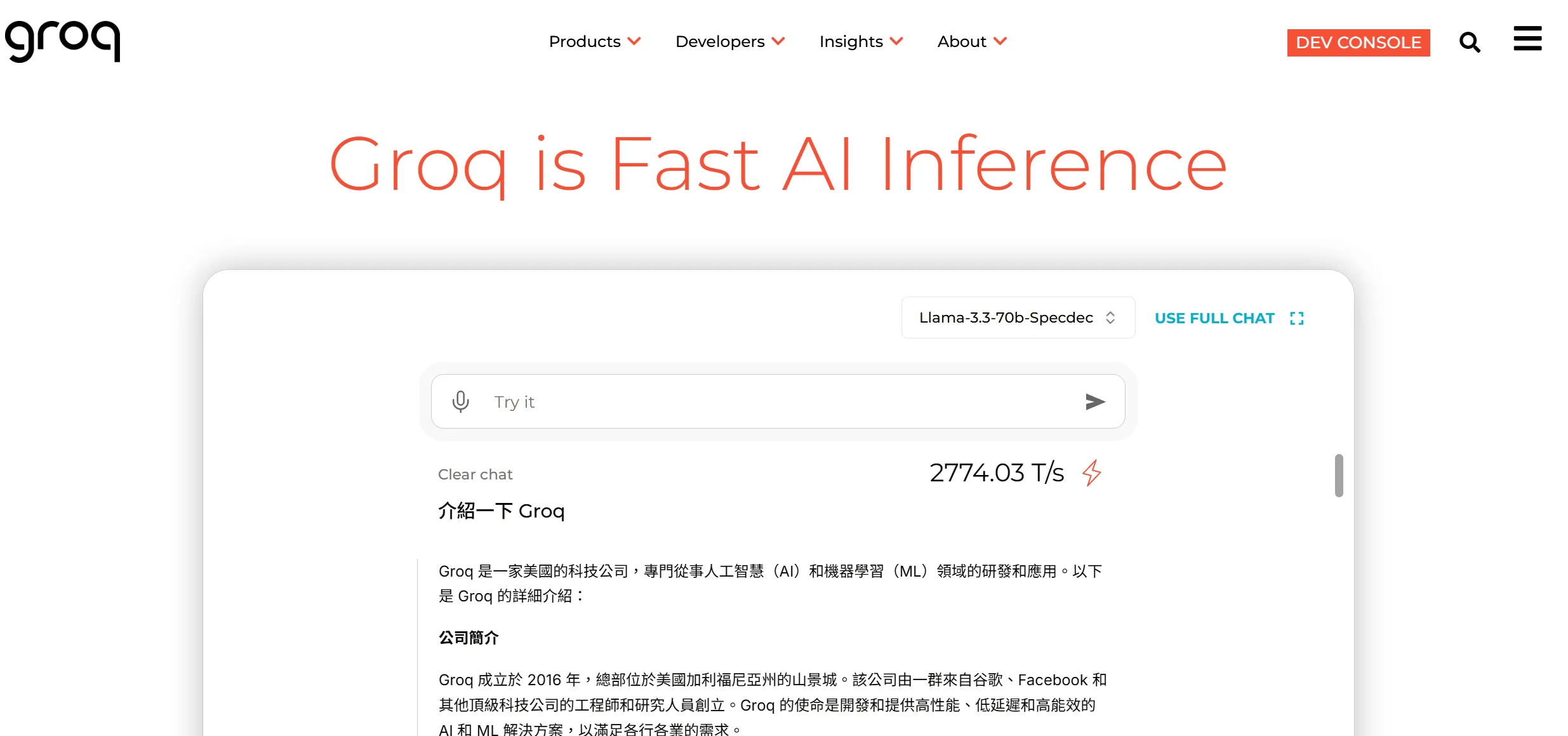
Groq 的 實驗性模型 llama-3.3-70b-specdec 在 GroqCloud 上的推論速度最快可以達到 1,660 tokens/s 。
- 低延遲 (Seconds to First Token Received)

- 高性能 (High Output Tokens per Second)

可以使用的 Models
- 可以在 https://console.groq.com/docs/models 查看可以使用的模型
- 目前多為 llama、gemma、whisper 系列
使用
可以在官方網站 https://groq.com/ 或是playground直接使用
API
https://console.groq.com/keys
在左邊 API Keys 的選單中點擊 Create API Key,目前免費層級有提供一定的額度使用,API 兼容 openai 格式,修改 base_url 和 model 後可以直接使用。
import os
import openai
client = openai.OpenAI(
base_url="https://api.groq.com/openai/v1",
api_key=os.environ.get("GROQ_API_KEY")
)Cerebras 介紹
Cerebras 研發的產品是 Wafer Scale Engine(WSE,晶圓級引擎),是一款 超大型 AI 加速晶片。

可以使用的 Models
- 可以在 https://inference-docs.cerebras.ai/introduction 查看可以使用的模型
- 目前只有 llama 系列
使用
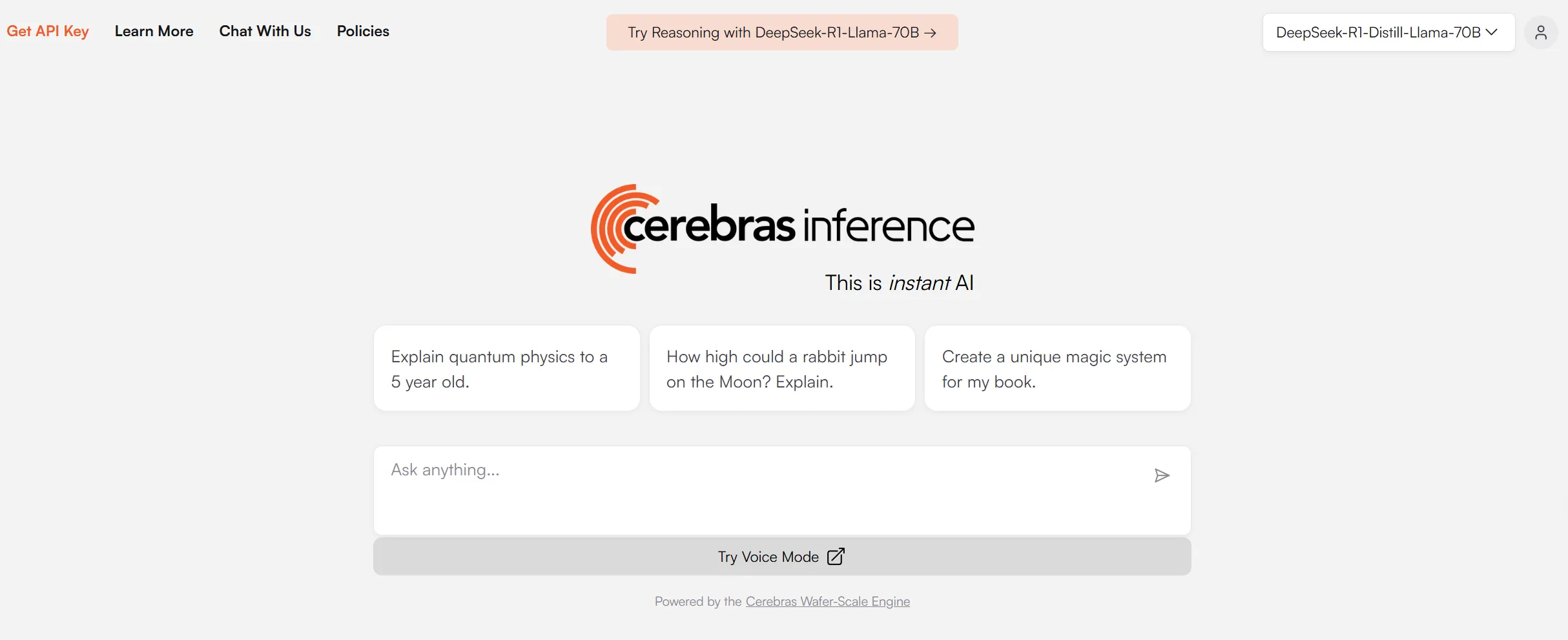
可以在首頁https://inference.cerebras.ai/直接使用
API
https://cloud.cerebras.ai/platform/
首頁右上方點擊 Get API Key,需要填寫 Google 表單申請,目前免費層級有提供一定的額度使用,
API 兼容 openai 格式,修改 base_url 為 https://api.cerebras.ai/v1 和 model 後可以直接使用。
Sambanova 介紹
SambaNova 開發的產品是 SN40L ,Reconfigurable Dataflow Unit (RDU),專為 AI 推理與訓練設計的整合式加速晶片。
- SambaNova 與其他競品的比較
- 來源
| 指標 | SambaNova SN40L | Cerebras WSE-3 | Groq LPU |
|---|---|---|---|
| 晶片數(70B 模型) | 16 晶片 | 336 晶片(4 晶圓) | 576 晶片 |
| 算力密度 | 優於 Groq 40 倍 / Cerebras 10 倍 | 高算力但受限於 SRAM 與多晶圓管線並行成本 | 需大量晶片互連以補足 SRAM 容量限制 |
| 記憶體架構 | SRAM + HBM + DDR | 全 SRAM | 全 SRAM |
| 量化需求 | 無(16-bit 原生) | 無(官方宣稱使用 16-bit) | 推測需 int8 量化 |
可以使用的 Models
- 可以在 https://docs.sambanova.ai/cloud/docs/get-started/supported-models 查看可以使用的模型
- 目前只有 DeepSeek、llama、Qwen 系列
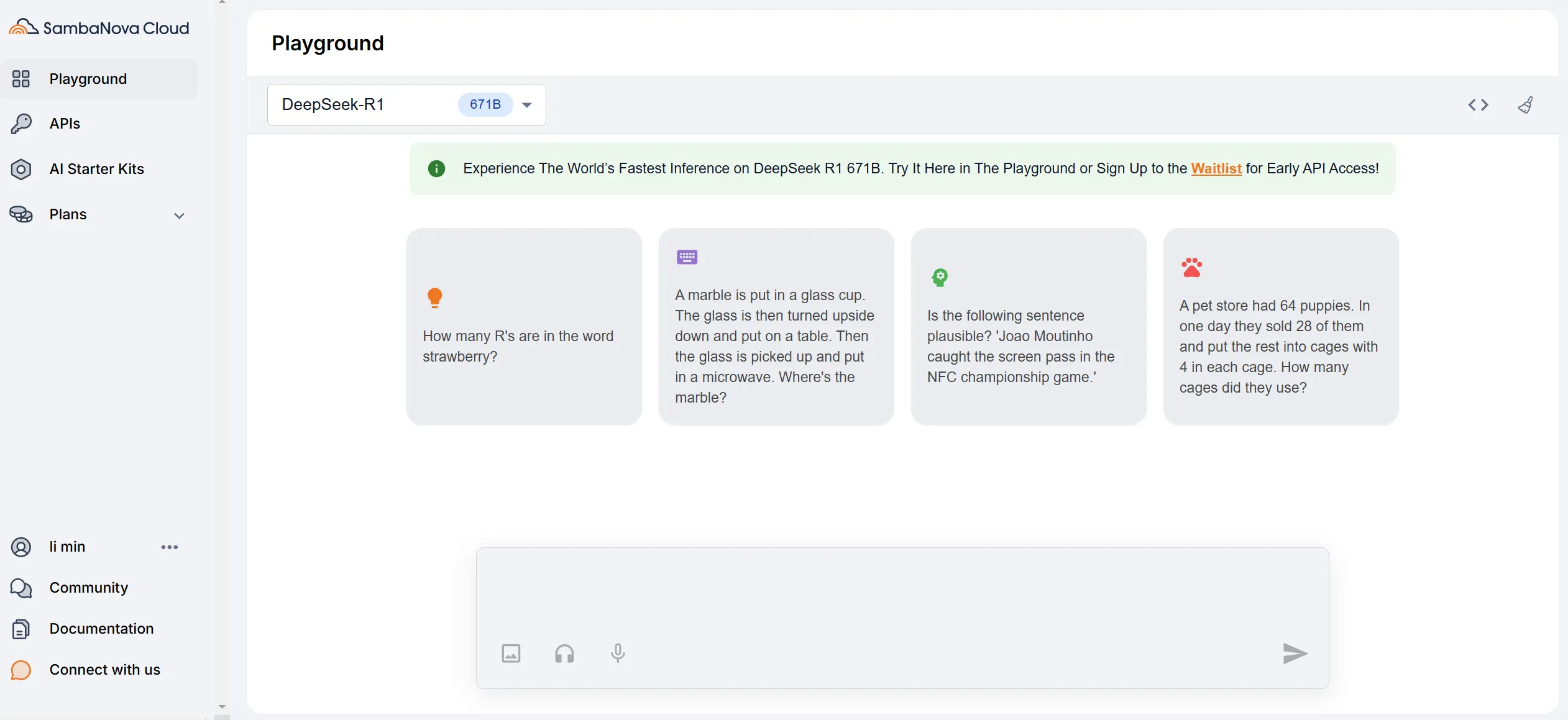
- DeepSeek R1 671B 需要填表申請
使用
可以在官方網站 playground直接使用
API
https://cloud.sambanova.ai/apis
在左邊 API Keys 的選單中點擊 Create API Key,目前提供新用戶 5 美元(3 個月到期),
API 兼容 openai 格式,修改 base_url 為 https://api.sambanova.ai 和 model 後可以直接使用。